|
■ 中央調査社のサンプリング
一般社団法人中央調査社 当社は世論調査・市場調査などの社会調査で国勢調査区を使用するサンプリングを行い、すでに60 年の実績を持つ。このサンプリングには、国勢調査区あるいは基本単位区を第1 次抽出単位とする層化二段無作為抽出を用いている。当社に限らず複雑で変化の激しい現代社会を理解するため、様々な調査設計を元に社会調査が実施されているが、当社では2011 年にIBM のホスティングサービスからサーバー・パソコン系システムへ移行したことにより、サンプリングシステムを改良し、機能の追加等を行い、業務の効率化を行った。今回、改めて当社のサンプリングについて述べてみたい。 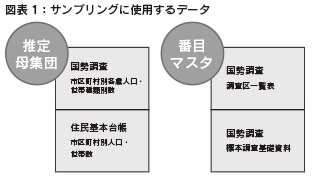 4. サンプリングの流れ まず層化にあたって、①母集団、②サンプル数、③ 1 地点当たりのサンプル数、④層化の基準(地域・都市規模)を決める。例えば、母集団を20 歳以上男女個人、サンプル数2,000、1地点当たりのサンプル数を15 前後とする。層化の基準は、地域は北海道・東北・関東・中部・近畿・中国・四国・九州の8 区分とし、都市規模は21 大市(政令指定都市、東京都区部)・その他の市・町村の3 区分とする。8 × 3 = 24 であるが、四国に21 大市はないので、計23 の層(セル)ができる。ここからサンプリングを始める。 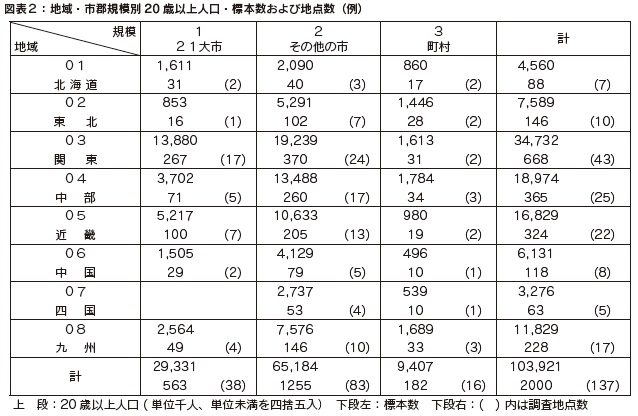 全国の20 歳以上の母集団数は平成26 年住民基本台帳人口から103,921,280 である。23 の層の1 つである北海道の21 大市(札幌市)の20歳以上の母集団数は1,610,971 である。2,000 サンプルを比例配分すると札幌市のサンプル数xは、103,921,280:2,000 = 1,610,971:xであるから、x = 1,610,971 × 2,000 / 103,921,280、x≒ 31 となる。31 サンプルを1 地点15 前後とすると、16 対象の地点と15 対象の地点、2地点が札幌市で立つことになる。なお、計算上は小数点以下が出るが、一人の対象者を分けることはできないので、整数でまるめることになる。同様に計算すると、北海道のその他の市の層では40 対象、3 地点。北海道の町村の層については17 対象、2 地点となる。このようにして2000 サンプルを、各層に配分していくと、137地点が設定される。この23 層の表を層化表と呼んでいる。 各層の母集団に応じた対象数、地点数が配分された後、一段目となる地点の抽出を行う。地点抽出にあたり、当社では国勢調査の基本単位区または調査区を使用しているが以後は基本単位区の利用を前提として述べる。1 つの層で複数地点を選ぶ場合、その層の国勢調査時の20歳以上人口を地点数で割り、それを抽出間隔(インターバル)とする。ここで、前項で述べた「番目マスタ」を使用し、スタートNo. をランダムに決め、該当番目の人を含む基本単位区を1 地点目とし、その次から計算した抽出間隔を数え、該当番目の人を含む基本単位区を2 地点目とする。このように地点を選び、二段目の抽出の起点とする。例えば、2 地点が当たっている北海道の21 大市、つまり札幌市は、平成22 年国勢調査時の20 歳以上の人口が1,591,212 なので、地点の抽出間隔は1,591,212 / 2 = 795,606 である。乱数によるスタートNo. が120,000ならば、1 地点目が120,000 番目の人を含む基本単位区となり、2 地点目が120,000+795,606 = 915,606番目の人を含む基本単位区となる。次に、1 つの層で1 地点を選ぶ場合、例えば、東北の21大市、つまり仙台市では16 対象1地点なので、ランダムな数字を発生させ、該当番目の人を含む基本単位区を地点として決める。 次に、二段目で対象者を選ぶことになる。各地点でスタートNo. をランダムに決め、調査ごとに適宜決めている一定の抽出間隔で対象者を抽出していく。抽出間隔番目の人が対象適格でない場合(19 歳以下)は、再度間隔を数え直して、対象適格者(20 歳以上)であれば、対象者として抽出する。 当社では、主に住民基本台帳(リスト)や選挙人名簿抄本(「政治・選挙に関する調査」に限られる)を台帳としている。住民基本台帳(リスト)や選挙人名簿抄本は、原則非公開であるが公益性が高いと認められた調査の場合(住民基本台帳法第十一条の二、公職選挙法第二十八条の三)、その調査以外の目的では使用しないという誓約書を添えて閲覧申請をし、自治体や選挙管理委員会の許可が得られた場合には閲覧が可能である。 以上、20 歳以上の男女を例として、サンプリングの説明を進めた。母集団は様々考えられるが、推定母集団では各歳の人口もデータとしてあるので、例えば18 歳から79 歳の男女個人を母集団とすることなどもできる。また、二人以上普通世帯や単身世帯などを母集団とし、サンプリングを進めることもできる。 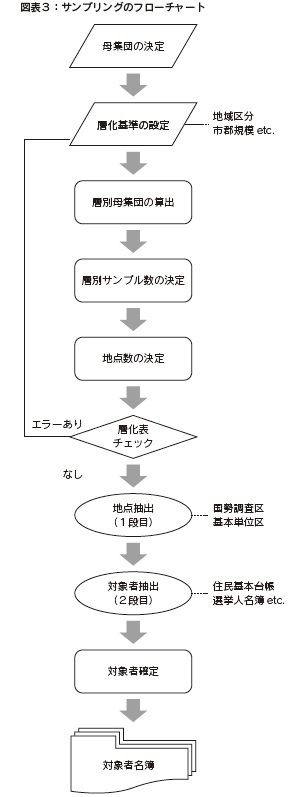 5. 国勢調査区利用上の注意 サンプリングに使用するデータ「国勢調査 調査区一覧表」における基本単位区の表記の関係で、調査地点として選ばれた国勢調査区や基本単位区が実際の住所のどこを指しているか、わかりにくい場合がある。例えば、「○○町の南部」「□□丁目の一部」、現在使われていない住所表記等、表現は多種多様である。住民基本台帳(リスト)や、選挙人名簿上でその地域を特定しにくい場合は、これらの表記を事前に国土行政区画総覧や地図等を参照して、地域を特定している。 当社のサンプリングでは、層化二段無作為抽出法を用い、一段目で国勢調査区や基本単位区を地点として選ぶ話をしてきたが、国勢調査区や基本単位区を用いないサンプリングに対応する関連システムの開発が現在進行中である。また、二段目の抽出の際に使用する、各自治体で管理されている住民基本台帳(リスト)は、現在並び順や整理の仕方が多種多様である。その他に2012 年7 月より外国籍住民がリストに含まれるようになり、抽出方法の特定が難しくなってきている。当社では、正確な抽出が行えるように、事前に並び順や整理の仕方を各自治体に確認し、抽出方法を特定している。また、抽出員への指示を適宜行い、抽出の正確さを強化している。今後、無作為抽出をする上で、代表性が損なわれないように更なる注意とレベルアップが望まれる。 |