|
■無作為抽出調査とインターネット調査におけるデータの質: 中間回答とストレートライニングの分析 NIRA総合研究開発機構 竹中勇貴
1.はじめに 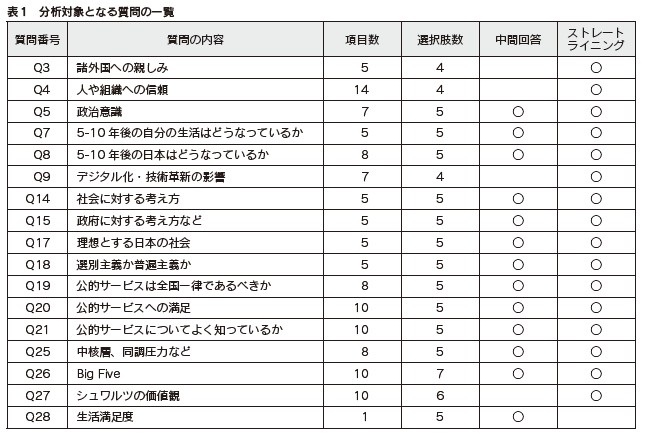
4.中間回答の分析 回答者が調査に取り組む労力を最小化しようとする場合、「どちらともいえない」などの中間的な選択肢を選ぶことが多くなる可能性がある。中間回答は、質問の内容が理解できない、つまらないなど、実に多様な要因によって生じうる。質問文を読むこともせず、機械的に中間を選択しているかもしれない。また、質問文をきちんと読んだ上で、意見がない、答えたくないといった理由で中間が選択されることもある(増田・坂上 2014)。 中間の選択肢を有する質問を対象に2、中間点が選ばれた割合を質問ごとに算出したのが図1である。マトリクス式質問では、マトリクス中の個々の質問項目ではなく、マトリクス全体を単位として、中間回答が占める割合を示している。 全体的な傾向として、中間回答の割合が最も多いのはインターネット調査でトラップ質問に正解しなかった回答者を含めた場合であった。次に多いのがインターネット調査でトラップ質問に正解しなかった回答者を除いた場合、一番少ないのが留置調査となっている。インターネット調査においては、トラップ質問に正解しなかった回答者を除くことで中間回答の割合が減少することが、すべての質問において確認できた。トラップ質問によって、適当に中間を選択する回答者を検出できていると考えられる。しかし、それでも留置調査と比べると中間点が選択される割合が高い傾向にある。 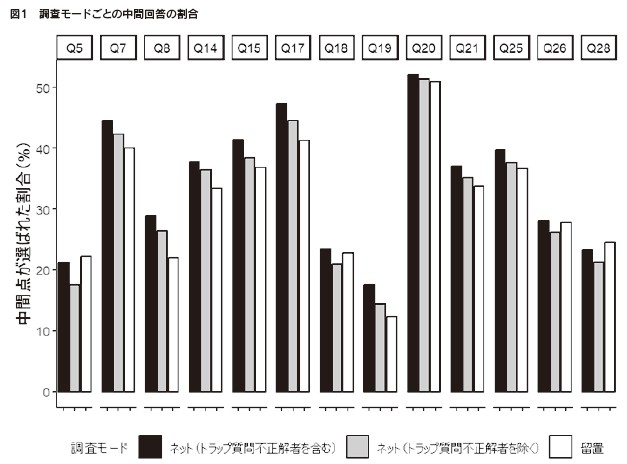
5.ストレートライニングの分析 5.1 完全なストレートライニング ストレートライニングもまた、回答者が調査に真剣に取り組もうとしなかった結果として生じうる行動である(山田・江利川2023)。個々のマトリクスにおいて、すべて同じ回答を選ぶという「完全なストレートライニング」を行った回答者をストレートライナーとし、その割合を調査モードごとに示したのが図2である3。 ほとんどの質問において、留置調査におけるストレートライナーの割合は、トラップ質問に正解しなかった回答者を除いたネット調査の水準と同じか少ない。 また、図2の質問は、左から質問票に登場する順番に並んでいる。質問票の後ろの方になるほど、回答者が疲れてストレートライニングを行いやすくなる可能性もある。確かに、ストレートライナーが多い質問は調査の後半に存在するように見えるが、最終盤の Q26とQ27ではストレートライニングがかなり少なくなっている。これらは、それぞれBig Fiveとシュワルツの価値観の質問であり、マトリクスの中で似た趣旨の内容を逆の言い方で聞くことをしているため4、真剣に回答すればストレートライニングとなる可能性は低くなる。また、政治や社会情勢に関する大半の質問とは違い、回答者自身に関する質問であり、回答に要する負担が比較的少なかったことが影響した可能性もある。 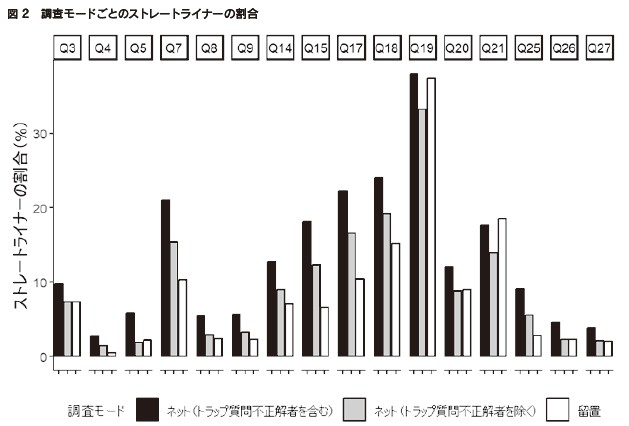
5.2 Mulliganスコア 前節の分析では、回答者を完全なストレートライニングを行ったか否かで二分したが、ストレートライニングは、回答の値が全体としてどのくらい似ているかという、程度の問題として捉えることもできる。例えば、すべて1ではなく、ほとんどが1だがたまに2を混ぜる、という回答行動もありうる。すべての回答値が同じか否かという二分法的な指標だけでは、そのような回答パターンを捕捉しきれない。 そこで、Mulliganスコアという指標を使用する(Kim etal. 2019)。Mulliganスコアとは、すべての質問項目のペアについて、回答値の差の絶対値の2乗根を取り、それを平均したものである。例えば、3つの質問項目を持つマトリクスで回答値が「1」「4」「3」であれば、ペアは「1と4」「4と3」「3と1」の3つなので、回答値の差の絶対値はそれぞれ3、1、2となり、Mulliganスコアは、√3、1、√2の平均である。このスコアは、回答の値が多様になるほど大きくなるという性質を持つ。数値を解釈しやすくするため、スコアは正規化している。 完全なストレートライニングが行われるとMulliganスコアは0となるため、Mulliganスコアは、前節の分析からストレートライニングの定義を連続的なものに拡張した指標であるといえる。ただし、Mulliganスコアは同じ回答値が連続するか否かには影響されない。例えば、「1, 1, 2, 1, 3, 1」と「1, 1, 1, 1, 2, 3」では、Mulliganスコアは同じ値になる。Mulliganスコアでは、同じ回答の連続性は析出できないという限界があることに留意されたい。 前節と同様に、マトリクスごとに回答者のMulliganスコアを計算し、その平均を示したのが図3である。繰り返しになるが、Mulliganスコアは小さいほどストレートライニングの傾向が強いことを意味する。全体的な傾向は図2と似ているが、図2ではQ19とQ21において、留置調査の方がトラップ質問不正解者を除いたインターネット調査の場合よりもストレートライニングが生じやすかったところ、図3では差はそれほど大きくない。Q20(公的サービスへの満足)とQ26(BigFive)では、留置調査の方がストレートライニングの傾向が強いという結果になった。 最後に、ストレートライニングのすべてが不良回答とは言い切れないという点には注意が必要である(Reuning and Plutzer 2020)。例えば、図2でも図3でもストレートライニングが際立って多いQ19は、医療や介護など複数の公的サービスを挙げ、それぞれについて、全国一律であるべきか、地域の実情を反映して違いがあるべきかを5点尺度で尋ねる質問である。回答者の中には、公的サービスの種類に関係なく、全国一律が望ましいと強く考える者も一定数存在すると考えられる。そのような回答者は、質問に対して真剣に考えた上で、すべて同じ選択肢を選ぶことになるだろう。 なお、留置調査ではインターネット調査と違って質問項目単位での無回答が存在するが、図2と図3はいずれも、無回答をすべて除外した上で分析している。つまり、マトリクス中の一部の項目に無回答があった場合、それ以外の回答のみを対象にして指標を計算している。また、マトリクスに含まれる質問項目に1つも回答しなかった回答者は、そもそも分析に含めていない。 
6.考察と課題 本稿では、同時期、同じ質問内容で、無作為抽出の留置形式とインターネット形式で実施された調査結果を使用して、中間点の選択とストレートライニングという観点から、回答データの質を比較した。 中間回答やストレートライニングの生じやすさは、そもそも質問の内容によって大きく異なったが、同じ質問でも調査モードによって違いが見られた。多くの質問において、中間回答とストレートライニングのどちらについても、インターネット調査より留置調査の方が少ないという結果になった。また、インターネット調査であっても、トラップ質問に正解しなかった回答者を除くことで割合は減少しており、トラップ質問に効果があることは示唆されたが、それでも留置調査の水準には至らないケースが大半であった。 ただし、これだけをもってインターネット調査より留置調査の方がデータの質が高いと結論づけるのは早計である。分析結果で見られた調査モードによる差の原因が、電子デバイスか自記式かという違いなのか、サンプル特性の違いなのかなど、判然としない部分もある。また、本調査では留置の場合とインターネットの場合で無回答をどの程度許容するかが異なっており、それが結果に影響している可能性もある。 無作為抽出調査とインターネット調査の比較というと、どうしてもサンプリング・バイアスの問題に目が向きがちであるが、本稿で分析したように、データの質もまた重要な問題である。調査における回答の質に関する研究は近年急速に進んでおり、今後も研究が必要なテーマといえよう。 注釈 1 https://www.nira.or.jp/paper/research-report/2025/252503.html 2 なお、本調査における中間回答は、すべて調査票における選択肢の並び順としても中央に位置している。 3 あるマトリクス式質問ではすべて1、別のマトリクス式質問ではすべて4を選んだ場合でも、双方の質問でストレートライナーとしてコーディングされる。 4 例えば、Big Fiveでは外向性を測定するために「活発で外向的だと思う」と、「ひかえめで、おとなしいと思う」という、逆の聞き方の2項目を置いている。 参考文献 ○谷口将紀・井上敦・竹中勇貴(2025)「NIRA基本調査2024:サンプルに含まれるバイアスと人々の意識変化」NIRA総合研究開発機構。 ○増田真也・坂上貴之(2014)「調査の回答における中間選択:原因、影響とその対策」『心理学評論』 57(4) : 472-94。 ○山田一成・江利川滋(2023)「ストレートライニングの検出と評価」『ウェブ調査の基礎:実例で考える設計と管理』誠信書房。 ○Hauser, David, J., and Norbert Schwarz. 2015. “It’ s a Trap! Instructional Manipulation Checks Prompt Systematic Thinking on “Tricky” Tasks.” SAGE Open . ○Kim,Yujin, Jennifer Dykema, John Stevenson, Penny Black, and D. Paul Moberg. 2019. “Straightlining: Overview of Measurement, Comparison of Indicators, and Effects in Mail-Web Mixed-Mode Surveys.” Social Science Computer Review37(2) : 214-33. ○Reuning, Kevin, and Eric Plutzer. 2020. “Valid vs. Invalid Straightlining: The Complex Relationship Between Straightlining and Data Quality.” Survey Research Methods14 (5): 439-59. |